Week 11 Blog - Recommender System And Continuous Deployment
In this post we will discuss λ Lovelace’s progress on the following:
- Recommender System
- Continuous Deployment
- Challenges & Next Tasks
Recommender System
As mentioned in the previous blog entry, the recommender system had to be de-coupled from the Twitter API so that tweets could be retrieved from the database and used in place. This resulted in the creation of the “RecommenderTextual.py” class. This class is essentially a stripped-down version of the recommender system thus far, now with some additions that the previous version did not have. For example, this version now takes tweet age into account and weighs tweets lower based on their age. A tweet can still rank highly based on their content, but a tweet that is almost a week old has virtually no chance of appearing in the users feed.
Tweet age weight is calculated as the age of the tweet (in seconds, from the “created_at” attribute) divided by the number of seconds in a week. The result is then divided by the max scale that is used for the term frequency document (10.0 at time of writing). The decision to normalise the age of tweets using the number of seconds in a week was an arbitrary decision made before any testing was performed on how this will affect user experience. This value will likely change, as the seconds-in-a-week value came from the week-old tweet limit that twitter imposes on third-party developers. As our tweets should not be much older than a week in the immediate future, this value will be fine for now. Testing is required to figure out the ideal timespan to weigh tweets over.
Another addition to this version of the recommender system is that it takes hashtags into account for the term-frequency document, and currently weighs them double the amount that a regular term is worth. This allows the recommender system to lend more importance to hashtags over regular terms, but the value of hashtags can be changed based on testing outcomes if necessary.
Lastly, punctuation and casing have been stripped from all terms added to the term frequency document. This allows for terms such as “Twitter!” and “Twitter…” to all fall under the umbrella term “twitter” for term frequency document purposes.
Continuous Deployment
We’ve touched on our continuous deployment plans in the past two blog posts. You are probably sick and tired of reading about it by now but we wanted to mention the setup we finally settled on after a lot of bumping into walls. The brief backstory is that we started using Heroku but switched to our own continuous deployment setup because the project requires a monorepository (doesn’t play well with Heroku). We bundle our app in Docker and tried few SaaS solutions without sucess; CircleCI, Distelli, and Docker Cloud.
Now on to what we finally settled on. Frustration was high but in a last ditch effort we tried Jenkins, an open source continuous integration and deployment software manually installed on our provided UCD virtual machine. We considered this in the beginning but opted for the SaaS solutions instead to save time. The irony.
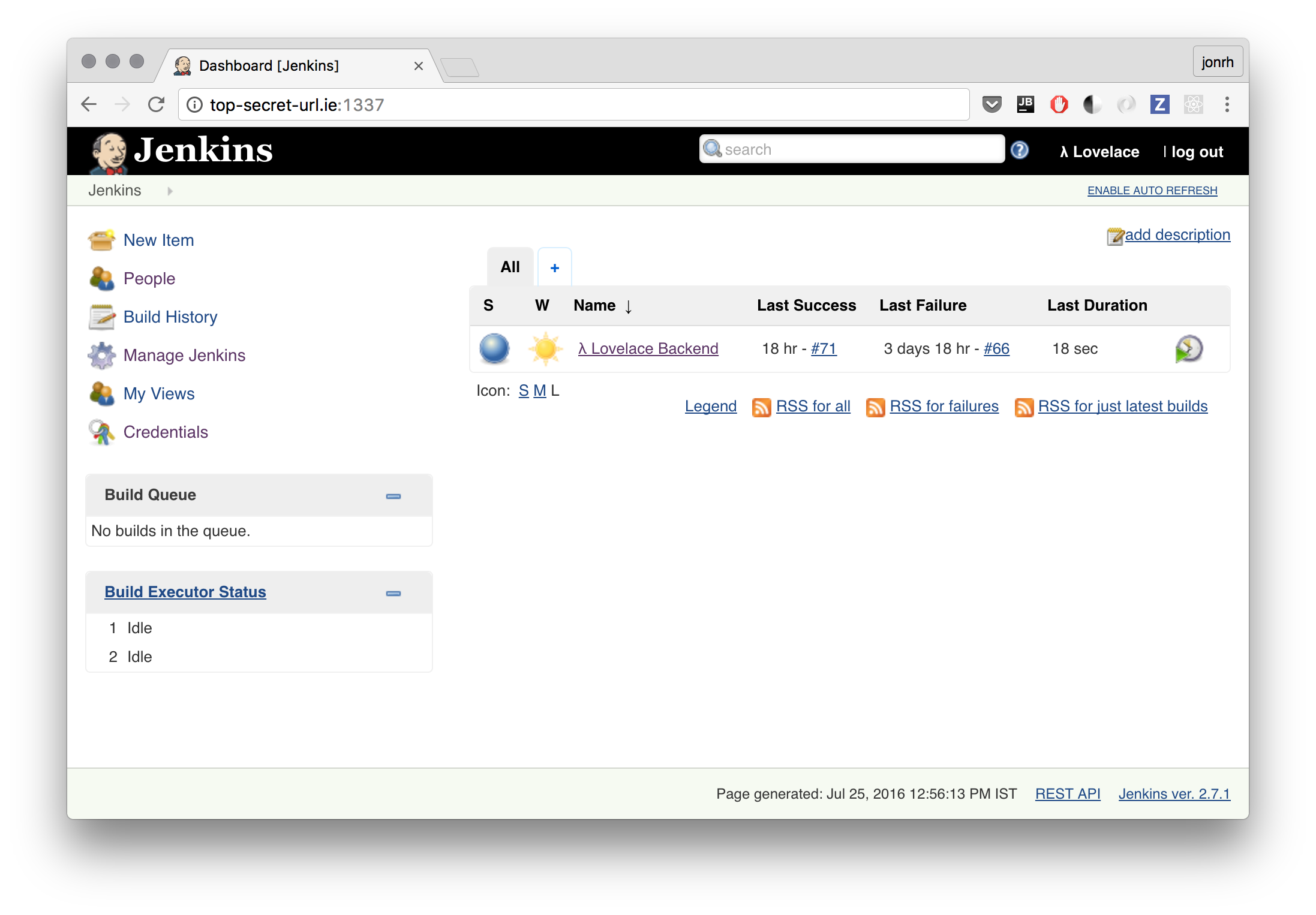
Setup was amazingly straight forward. Instead of special flavoured scripts (by each SaaS provider) our entire pipeline is described by the following shell script (18 commands):
# Move into the backend/ folder where our Docker image is located
cd backend
# Variable definitions:
# =============================================================================
# Define a variable to hold a short version of the git commit this build
# represents. E.g: "c721cdd"
GITHASH=$(git rev-parse --short HEAD)
# Jenkins build numbers are incrementing integers (1,2,3,...) for each build.
# Prefix it with a J in case we switch to some other tool than Jenkins. That
# way we can prefix it with different letter so we can tell the Docker image
# tags apart. Example: J1337
JENKINS_BUILDNUMBER="J$BUILD_NUMBER"
# The name of the Docker image. The "lovelace" part is the user name on Docker
# Hub. "/backend" is the image repository. Text after : is a tag (version).
# Example: lovelace/backend:J1337
IMAGE_NAME="lovelace/backend:$JENKINS_BUILDNUMBER"
# Build a docker image with the name lovelace/backend and tag.
# Example: lovelace/backend:J1337 where 1337 is the build number
docker build -t $IMAGE_NAME .
# Run our tests. If any fail this script will not continue executing.
docker run $IMAGE_NAME nosetests tests.py
# Image passed tests: tag the image we built with the tag latest
docker tag $IMAGE_NAME "lovelace/backend:latest"
# Log in to Docker Hub with user and pass credentials
docker login -u lovelace -p supersecretpassword
# Push to Docker Hub our new versions. They are the same so duplicate upload
# happens. We push both so we always have an "latest" image so we don't have
# to look up the latest build number if we need to manually start a container.
docker push $IMAGE_NAME
docker push "lovelace/backend:latest"
# Remove the previous container if it was running. The "|| true" bit is to
# have the build not fail if the container didn't exist. Note that for this
# script we always name our running backend container "backend-running". This
# is more of a dirty hack. The alternative would be to name it with for
# example Jenkins build number but I'm not smart enough to look it up to shut
# down a previous container.
docker rm -f backend-running || true
# Start and run the new container
# + give the container the name "backend-running"
# + -p 80:80: map port 80 of the host to port 80 in the container
# + -e: passes in environment variables. We use two, the Jenkins build number
# and the short Git hash of the latest commit. This is then used in the
# root / endpoint in the Flask app, so we can easily see which version
# is being currently run. Example: http://top-secret-url.ie/
# + --detach: runs the container in a background process, i.e. doesn't attach
# to the stdin/out
docker run --name="backend-running" -p 80:80 -e JENKINS_BUILDNUMBER=$BUILD_NUMBER \
-e GITHASH=$GITHASH --detach --restart=on-failure:50 $IMAGE_NAME
# The Docker CLI program gave some issues with signing in multiple times. To
# fix it I simply log out after the build is complete and sign in again when
# the next build starts. In and out.
docker logout
# The code below sends a notification to Rollbar (our logging service) that
# a new deployment ocurred. I don't have any idea what this all does, it's
# just a copy paste as instructed from Rollbar.
ACCESS_TOKEN=topsecrettoken
ENVIRONMENT=production
LOCAL_USERNAME=`whoami`
REVISION=`git log -n 1 --pretty=format:"%H"`
curl https://api.rollbar.com/api/1/deploy/ \
-F access_token=$ACCESS_TOKEN \
-F environment=$ENVIRONMENT \
-F revision=$REVISION \
-F local_username=$LOCAL_USERNAME
We host our Docker images on Docker Hub (think of it as GitHub but for Docker images). We did run into issues where Docker Hub would sometimes choke and timeout while pushing new versions. To solve it we simply retry building until it succeeds or fails after 3 times.
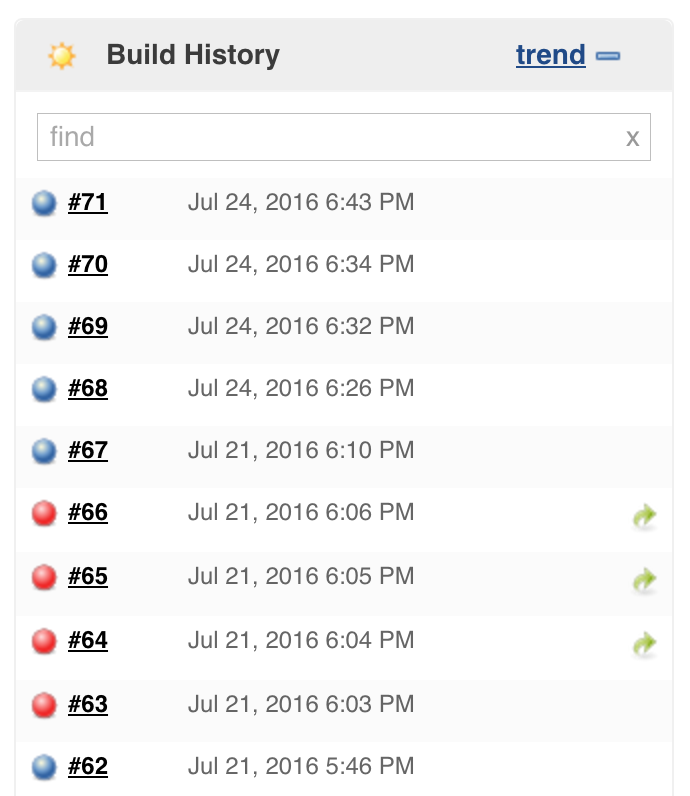
In addition to Docker and Jenkins we signed up for few extra services:
- Rollbar: If an exception or crash occurs in our Python backend or iOS frontend apps it’s registered and aggregated in Rollbar. No error shall pass by us!
- updown.io: Our backend answers on a publicly available endpoint. updown.io is a simple service that pings that endpoint and lets us know if our backend becomes unavailable.
Here is modified screenshot of what our Slack channel looks like. It shows Marc pushing new changes for the recommender system but with a minor syntax error (missing : at the end of a line).
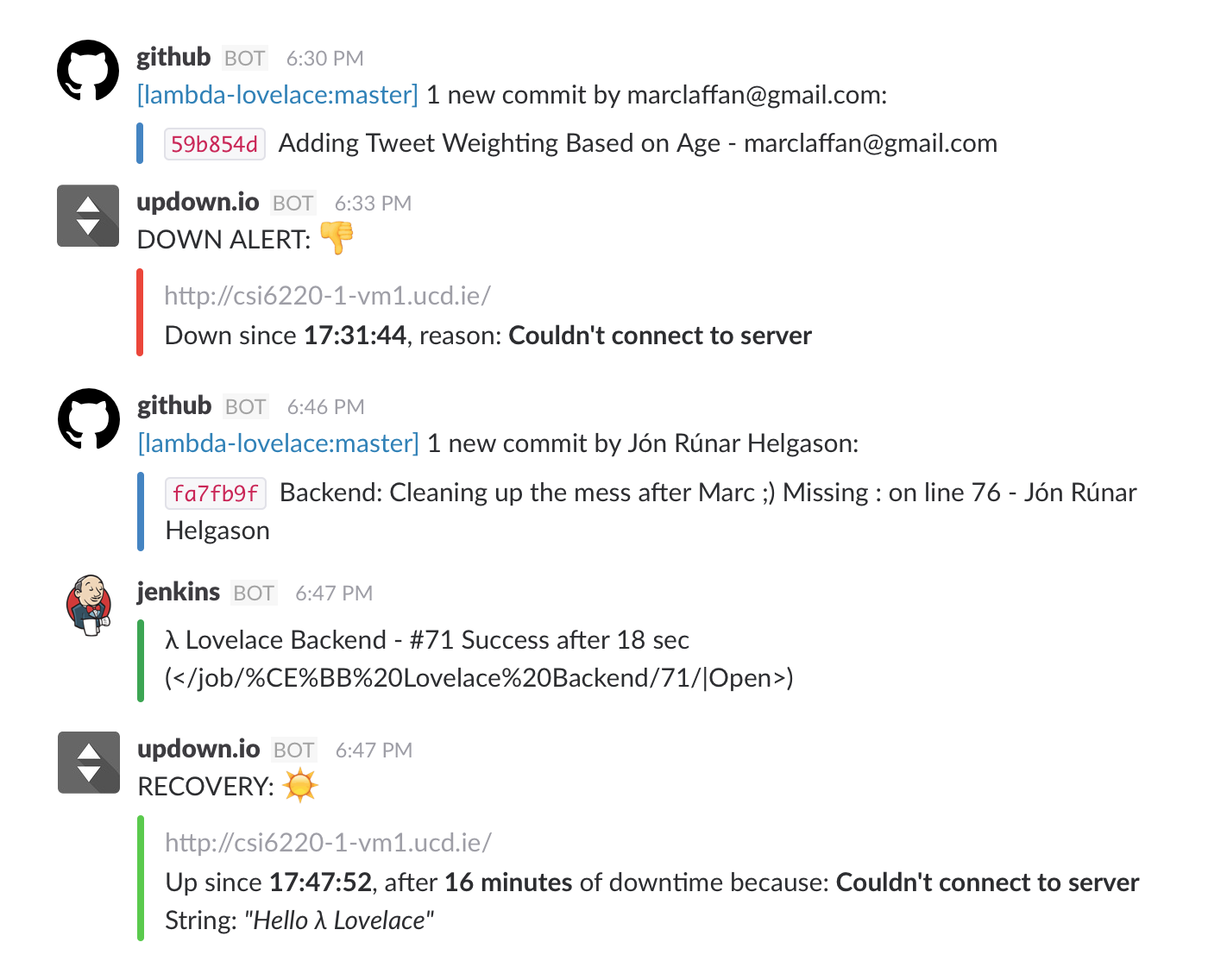
With the setup we have it took us only a few minutes to identify the problem, fix it and the changes got automatically deployed. Setting up this environment up took more time that we would have liked but we are hopeful the investment will pay off for the remaining 4 weeks of coding.
Challenges & Next Tasks
-
Recommender System: Next steps for the recommender system will involve the implementation of the “like/dislike” feedback functionality into the recommender system. Plans so far include placing any likes/dislikes into the same document/stored location as the tweet itself, so that it appears as an attribute of the tweet in the database, albeit one that is added by us. From here the likes/dislikes can influence the weighting of tweets. Testing is required to evaluate which method of implementing the like/dislike feedback is most effective for users, as the effect can either be immediate (One dislike immediately drops the value of all keywords in the term frequency document) or gradual (Immediate affect, but to a much less harsh degree. This would require more feedback over time and is the “safer” approach).
-
Evaluations: The next step in the evaluation process will involve running pilot tests amongst our friends and families in order to get feedback. The biggest challenge for the evaluation process will be finding enough people for a subjective evaluation.
-
Celery & Twitter API: The next steps for our Celery and Twitter API development will involve deployment onto a virtual machine and observe performance for one week.
-
Testing: With our continuous deployment environment firmly in place a remaining task is to write better tests for our backend. Currently we only do a simple 1 + 1 = 2 test. What remains is to write tests that better exercises our backend to reveal potential problems.
Until next time, on behalf of λ Lovelace.
- Marc Laffan