Week 9 Blog - DB, Docker, CI/CD
In this post we will provide an update on what λ Lovelace has been up to:
- Database Selection
- Docker
- Continuous Integration & Deployment
Database Selection
As mentioned in last weeks blog we were in the middle of evaluating a database solution. But before we get to that we want to share how we went about finding the right picks. Here are some of the requirements we had:
- store details on Twitter users registered for our service
- store interaction events from iOS client (like, dislike, tweet in view for X seconds, etc.)
- store results from user evaluations
- store a cache of tweets (JSON) to work around the Twitter API rate limits
- must have Python bindings
The JSON returned from the Twitter API is quite big so we decided early on it was not worth the time to encapsulate it in a rigid SQL schema. Instead we decided pretty early on to simply dump the JSON as is.
Here are the databases we took a look at:
We tracked our selection process in a GitHub issue that got quite big but below are some of the summaries. Here are links we use get a sense rankings between NoSQL databases:
Databases we eliminated pretty early:
- Redis: In-memory key-value store. Not exactly what we need.
- MySQL: From blog posts and change logs we got the impression PostgreSQL was a bit ahead of MySQL in JSON support. We therefore didn’t take much further look.
- EleasticSearch: Originally we thought ElasticSearch was only a search engine but apparently it’s a document database as well. We found the official website to contain only ambiguous and general marketing material.
Crate, MongoDB, and Couchbase were real contenders but RethinkDB and PostgreSQL came on top.
PostgreSQL
Although PostgreSQL is a SQL database it does have support for JSON. Over the years Postgre has been adding more and more support, most recently in the 9.5 version support was added for modification functions.
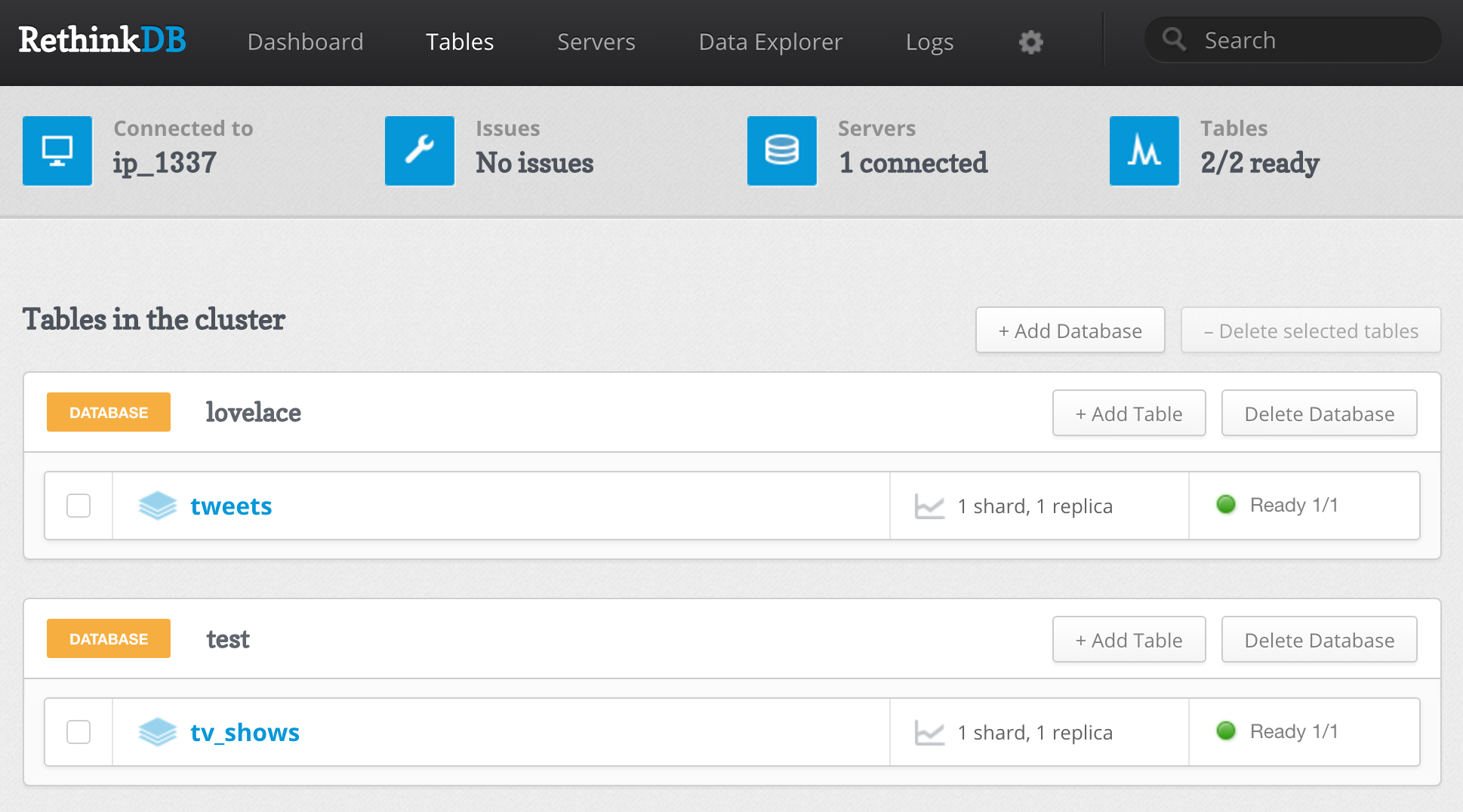
RethinkDB
- Most popular document database on GitHub by stars
- Comprehensive and good developer documentation
In our review we saw multiple blogs claiming the same thing: NoSQL databases are great for developer productivity but a questionable choice for long term data integrity. Since our project is time slotted to 14 weeks we decided to start out with storing all data in RethinkDB. We hope that going for NoSQL only will grant us increased acceleration in development and an opurtunity to work with a new technology. However we have decided if things don’t work out we will fall back to the familiarity of PostgreSQL.
Currently RethinkDB is running on a T2.Micro virtual machine in Amazon Web Services.
Docker
Our backend consist of a Python web service in Flask and the recommender system uses scikit-learn. Scikit-learn requires considerable dependencies underneath (for example a Fortran compiler). The team had some setup issues between computers. We decided to give Docker a try to flesh out those issues. We saw that Team Black (Newsfast) experienced similar issues and they reported Docker was an initial time investment that paid off as the project went along. We hope we can repeat the same.
Currently our Docker file is pretty simple. We base it on an official Python 2.7 image with a built in on-build command. Essentially, it assumes the presensce of the file requirements.txt and install all Python dependencies as needed. Here is the content ouf our Docker file:
FROM python:2-onbuild
EXPOSE 5000
CMD ["python", "Lovelace.py"]
Currently we are utilising the virtual machine provided by UCD. It’s a 1x core, 2GiB RAM, 100GB hard drive machine. It should be enough but we might want to migrate to a more powerful machine. Since we use Docker that migration will be an effortless move.
Continuous Deployment
Up until now we had been using Heroku to deploy our backend. It was however troublesome to use because one of the requirements of the project is to use a single repository which we will turn in at the end of the module. Every time we deploy to Heroku from a subdirectory in our mono repository we’d get Git errors which required tedious work to resolve on every push.
We therefore set ourselves to set up a proper environment where we could simply push code to our repository and our backend would automatically update. This is currently still a work in progress.
iOS App Screenshot
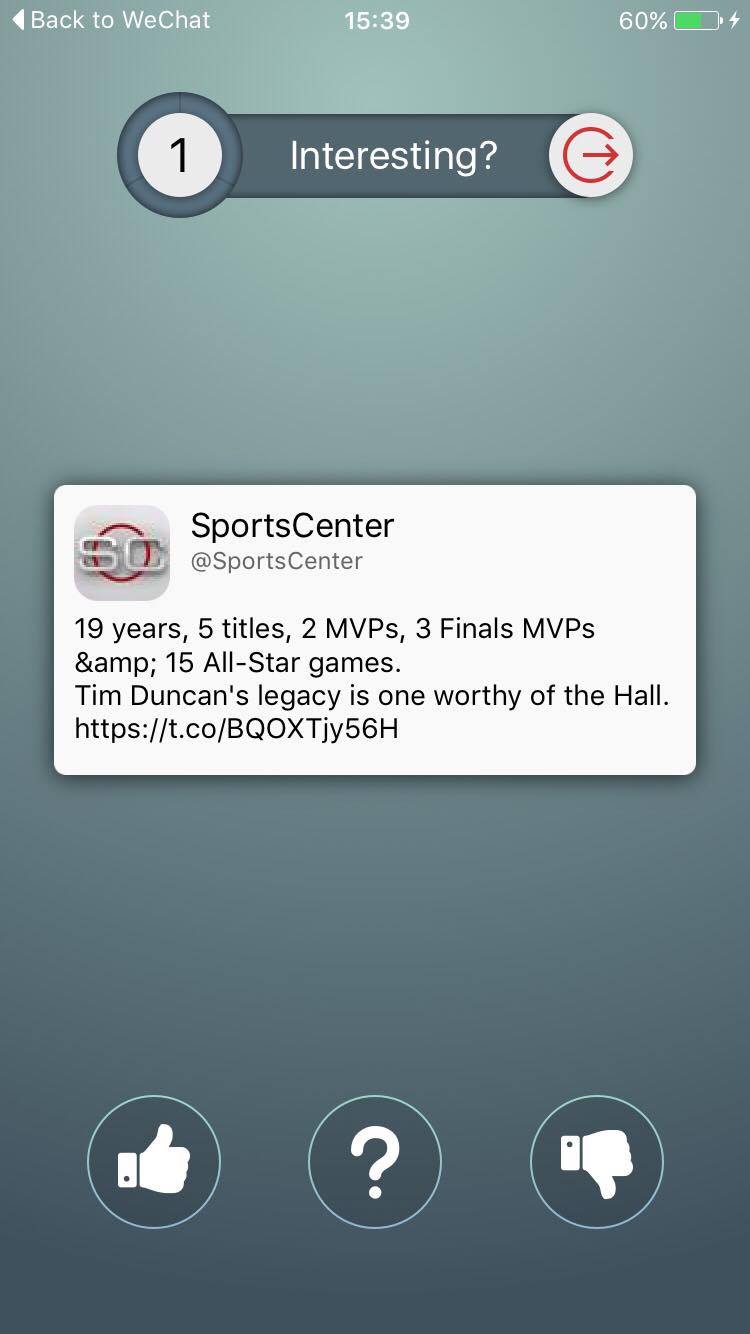
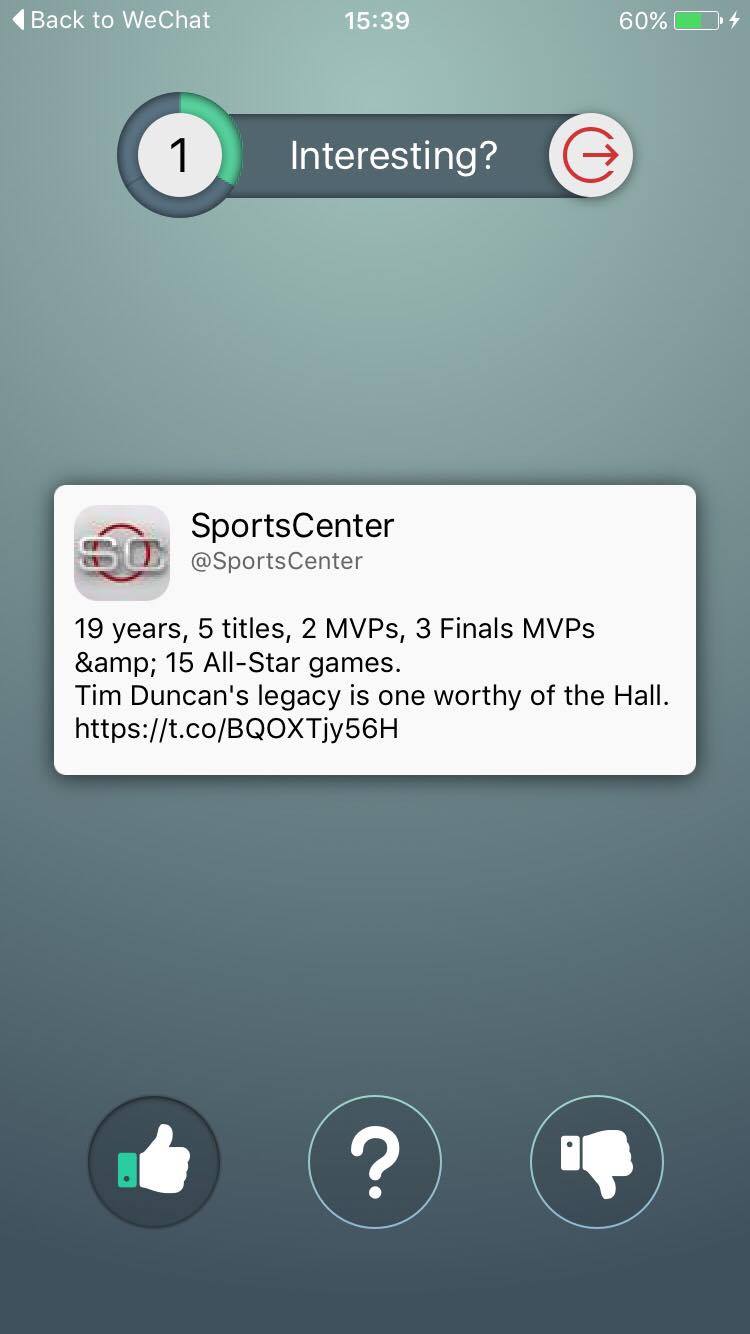
User Evaluation Screenshots

Challenges & Next Tasks
- Recommender System: fix a lot of bugs and incorporate feedback from the client. Challenges would be how we’re going to store and use this data.
- iOS App: sending the user interaction data to the Flask API
- Continuous Deployment: Finalise so everything deploys on every push.
- Flask API: Celery tasks have been set up. Next up is to save tweets to RethinkDB.
Until next time!
On behalf of λ Lovelace
- Jón Rúnar Helgason